Research4h ago
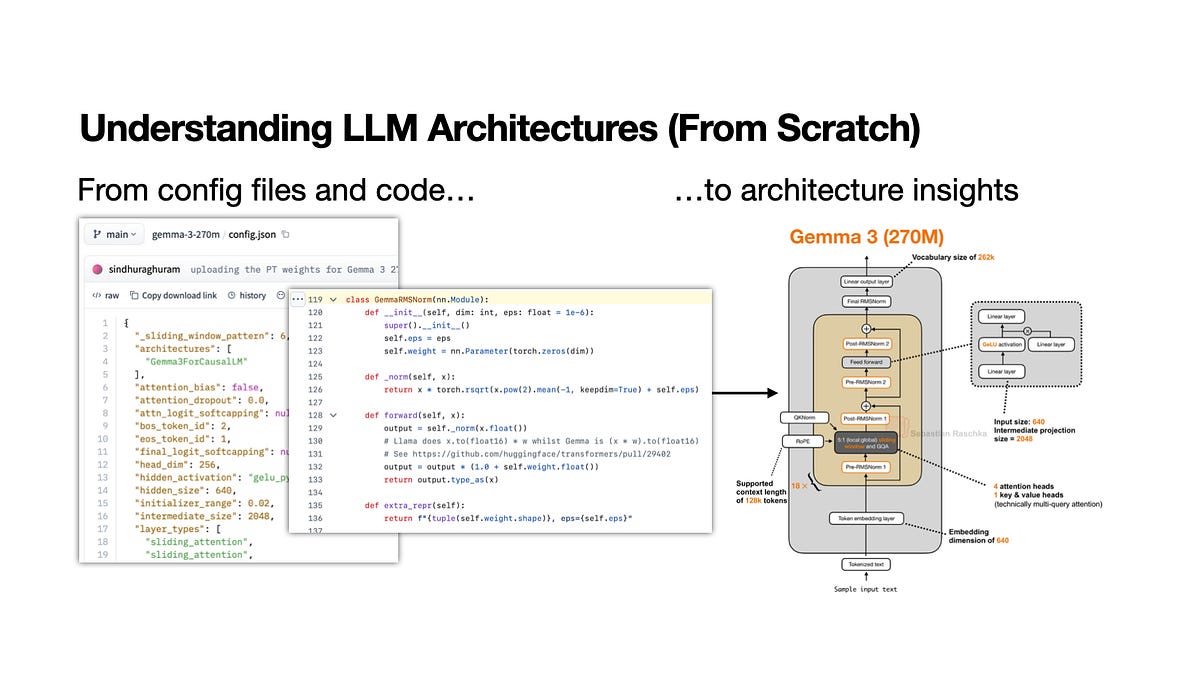
A Framework For Analyzing Open-Weight Models
This workflow prioritizes a structured approach to dissecting new open-weight model releases. It focuses on mapping architecture changes to specific performance gains. By isolating these variables, researchers avoid the noise of marketing benchmarks. This method provides a repeatable template for developers to evaluate LLM efficiency and scaling laws without wasting compute.