Model1h ago
RadixAttention Integration Hits Trellis
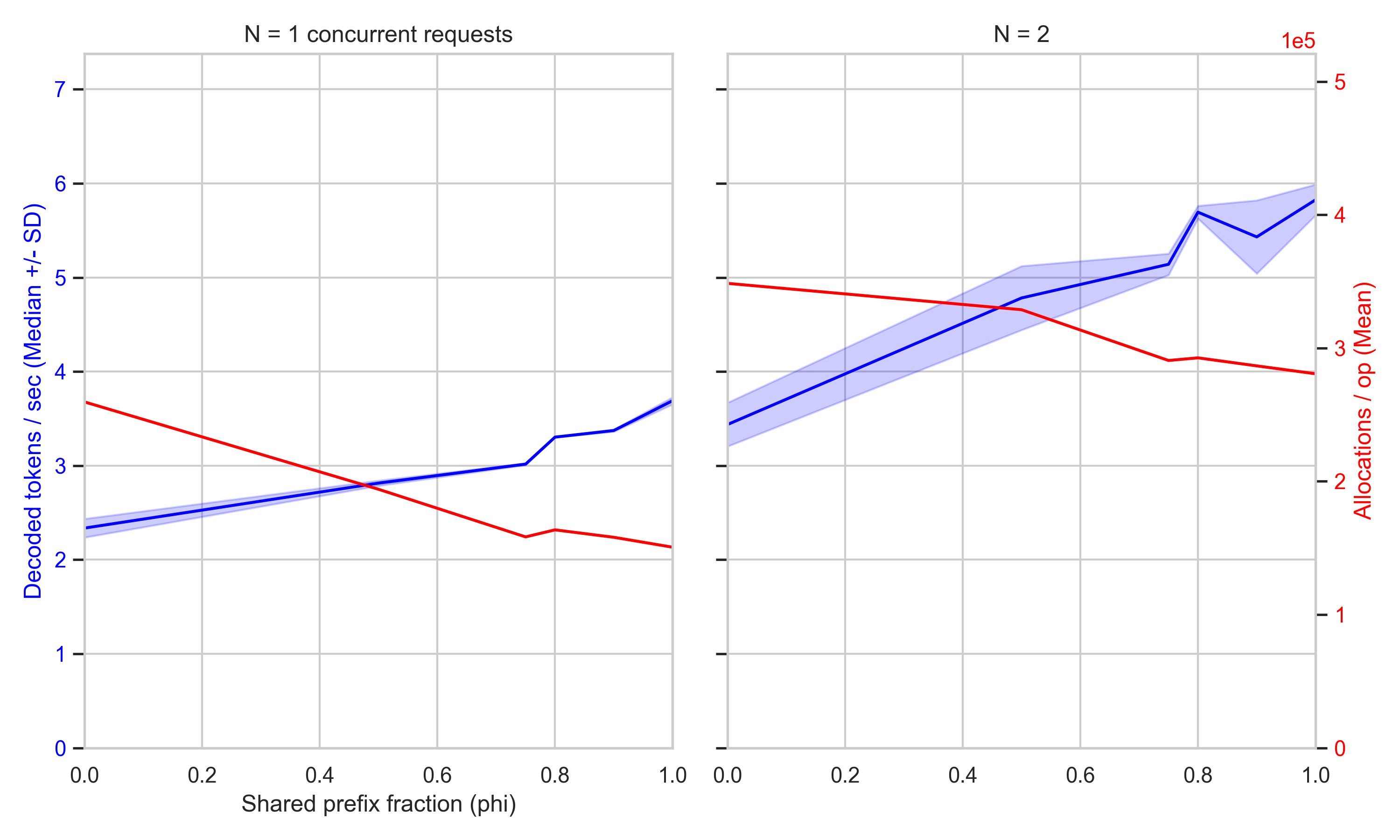
The Trellis framework now integrates RadixAttention to optimize KV cache management. This update reduces memory overhead during long-context inference by reusing previously computed attention keys and values. Developers can now handle larger batches with lower latency. It is an incremental performance gain for those deploying large-scale generative models in production.