Research4d ago
RadixAttention Integrated Into Trellis
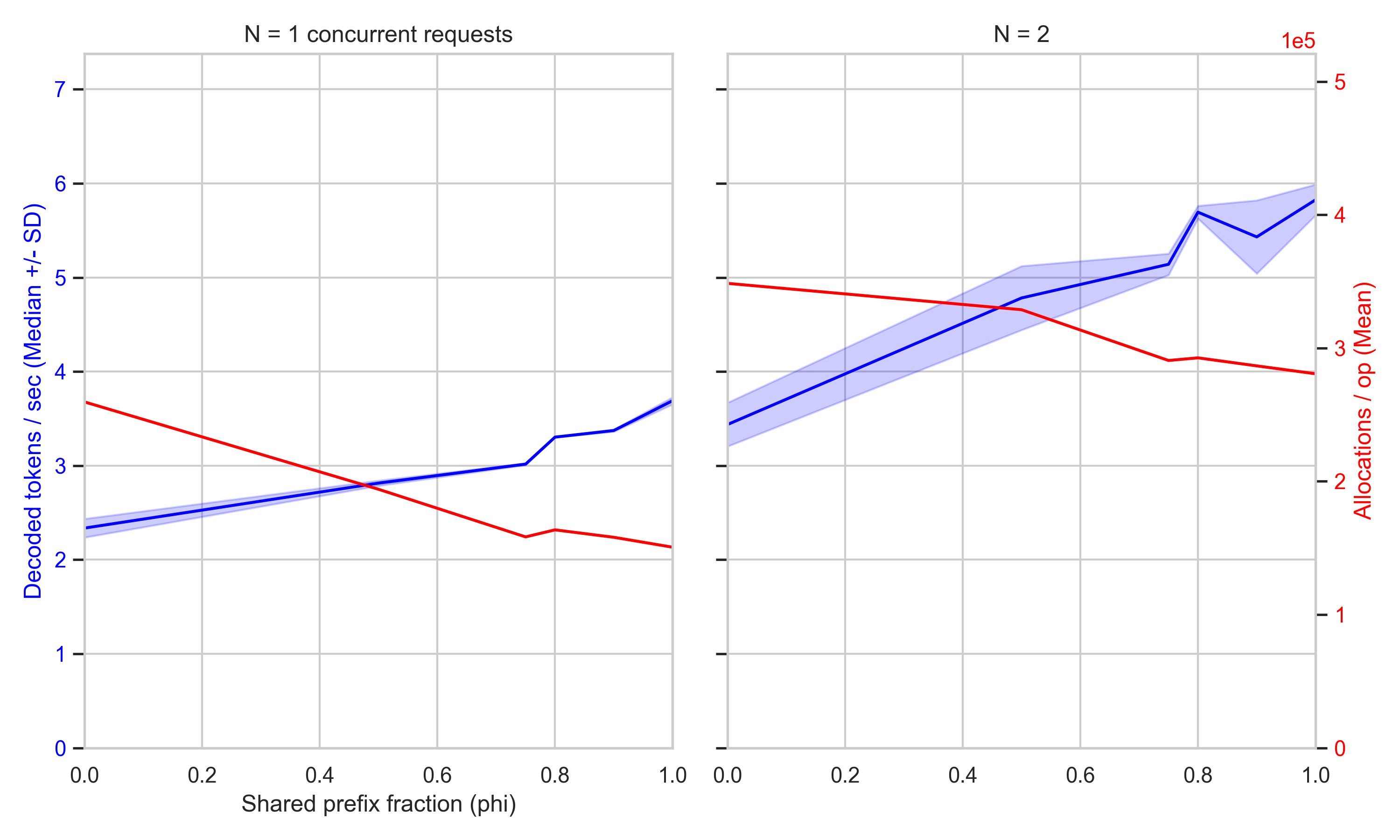
The Trellis framework now integrates RadixAttention to optimize KV cache management. This update reduces memory overhead during long-sequence generation by sharing common prefixes across different requests. It targets specific efficiency bottlenecks in large-scale inference. Developers can now achieve higher throughput without increasing hardware requirements for complex generative tasks.