Research4d ago
RadixAttention Integrated Into Trellis
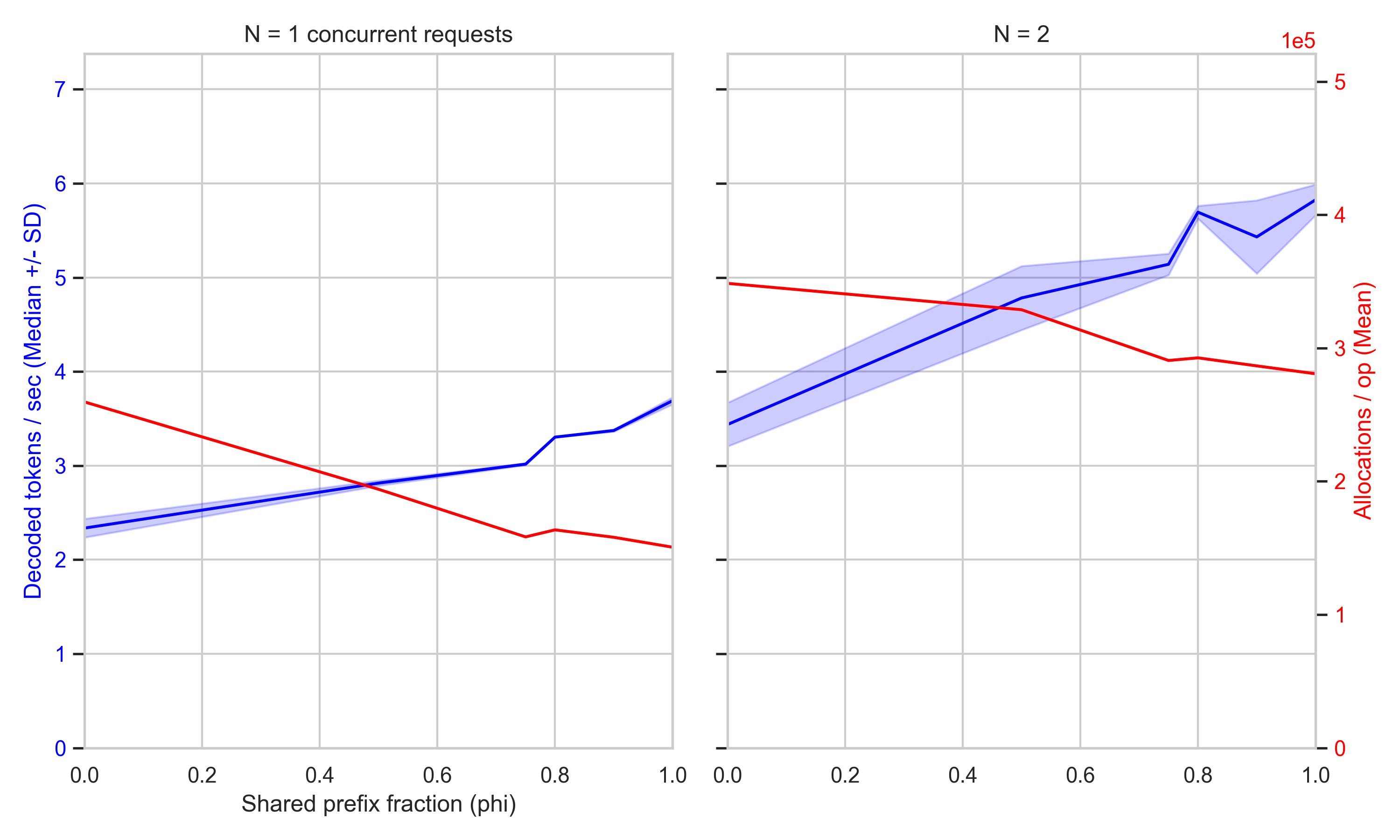
The Trellis framework now integrates RadixAttention to optimize memory usage during inference. This mechanism caches common prefix keys and values, reducing redundant computations in large-scale generative tasks. It speeds up processing for repetitive prompts. Developers can now achieve lower latency without sacrificing model precision in complex 3D asset generation workflows.