Model10h ago
Trellis Integrates RadixAttention For Efficient Inference
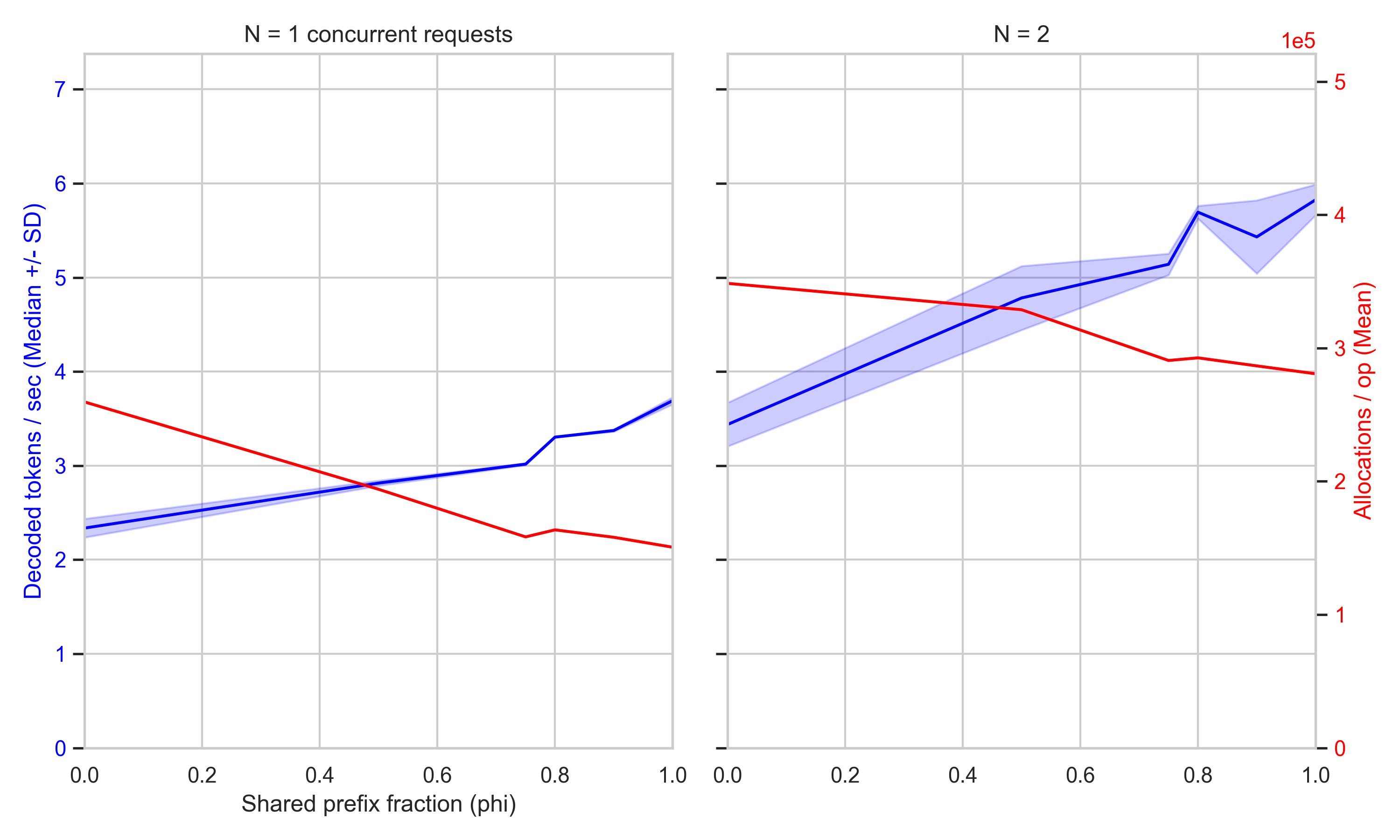
The Trellis framework now incorporates RadixAttention to optimize key-value cache management. This update reduces memory overhead by sharing common prefixes across multiple requests. It speeds up inference for long-context sequences. Developers can now deploy larger models on constrained hardware without sacrificing throughput or increasing latency during repetitive prompt processing.