Tools3h ago
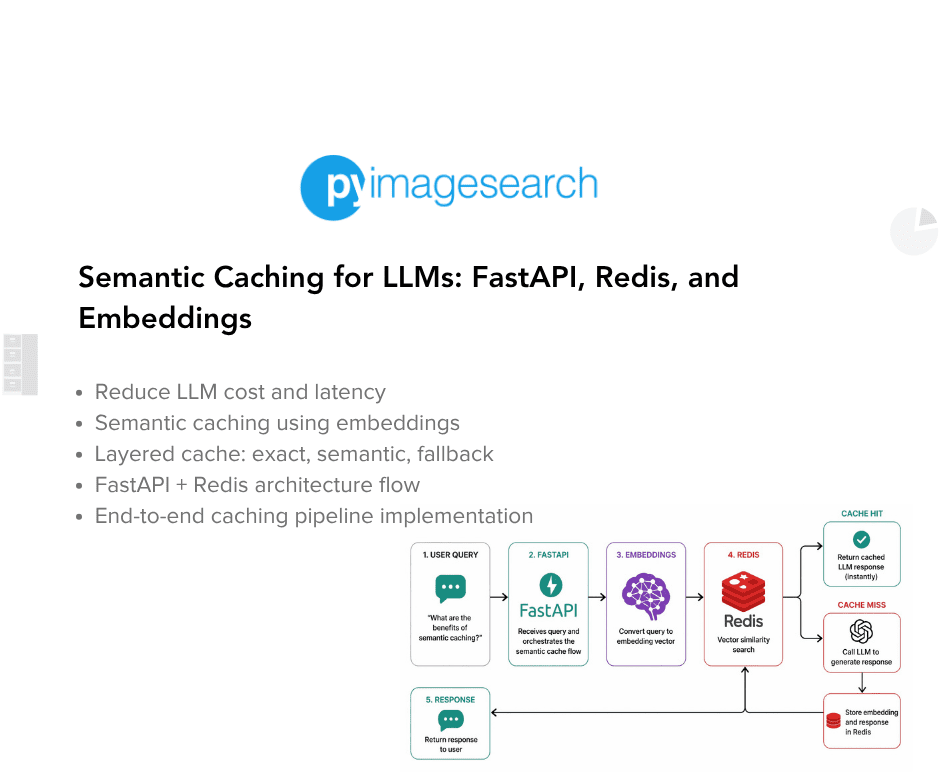
Implementing Semantic Caching With Redis And FastAPI
Redis and FastAPI enable semantic caching by storing LLM responses as vector embeddings. Instead of exact keyword matches, the system uses similarity searches to retrieve cached answers for conceptually similar queries. This architecture reduces API costs and latency. Developers can now bypass expensive model calls for repetitive prompts without sacrificing response accuracy.