Model5d ago
RadixAttention Integrated Into Trellis
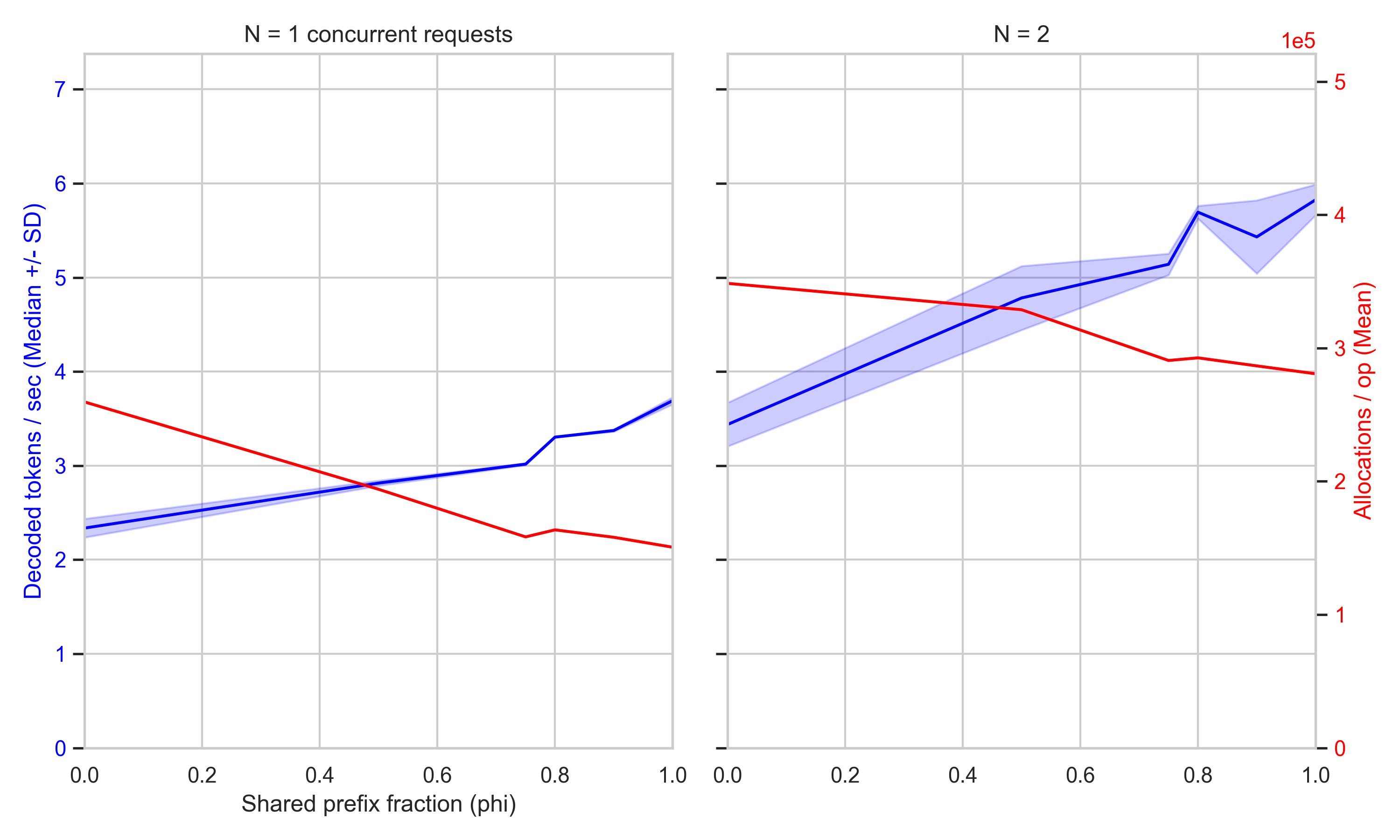
The Trellis framework now integrates RadixAttention to optimize KV cache management. This update reduces memory overhead during long-context generation by sharing common prefixes across sequences. Developers can now handle larger batches with lower latency. It is an incremental efficiency gain for those deploying 3D asset generation models at scale.